
지난 포스팅까지, 스타일 이름을 가져오는 과정을 마쳤습니다.
이번에는 유사하지만 미묘하게 다른 단어들끼리 매칭할 때 많이 사용되는 파이썬 내장모듈인
difflib의 SequenceMatcher를 활용하는 방법을 알려드리겠습니다.
지금까지 이 고생을 해서 스타일 이름을 가져온 이유를 다시 상기해보면,
취합문서의 스타일 이름이 템플릿문서 대비 전부 미묘하게 바뀌어 있고
특히 템플릿의 스타일과 취합문서의 스타일 순서가
뒤죽박죽이 되어버렸기 때문입니다. (극단적인 예를 들었습니다.)

위 엑셀파일에는 취합문서 스타일의 이름이 템플릿 문서의 스타일과 전부 다릅니다.
여기 SequenceMatcher를 도입하면 어떨까?
그럼 SequenceMatcher의 사용법에 대해 간략히 보여드리겠습니다.
사실 SequenceMatcher가 많은 일을 해 주는 건 아니고,
간단히 두 문자열의 유사도를 출력하는 데 쓸 겁니다.
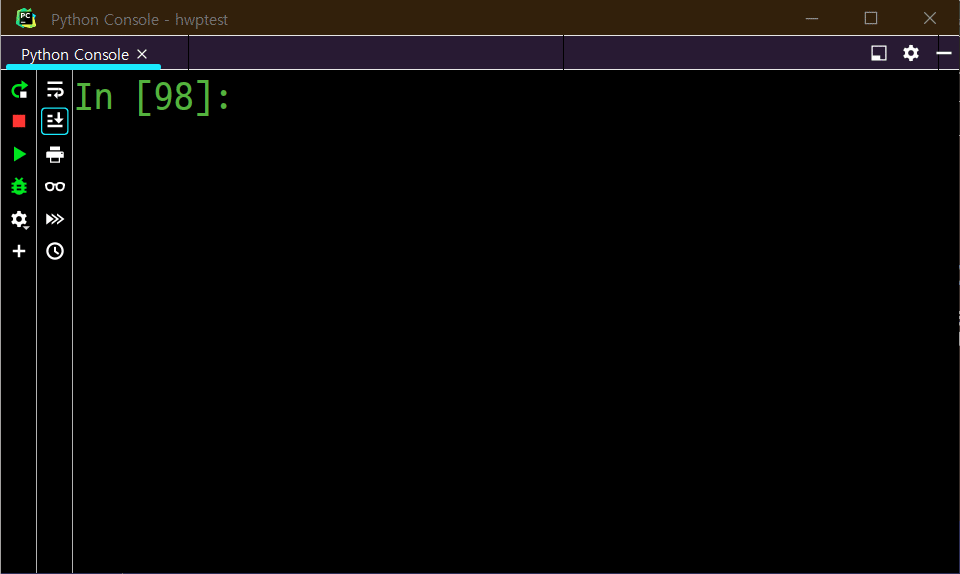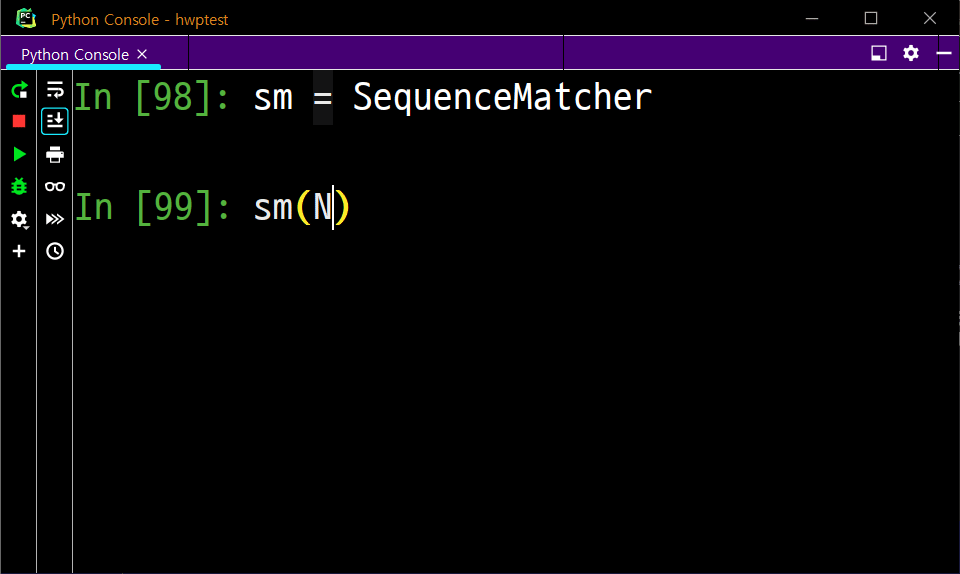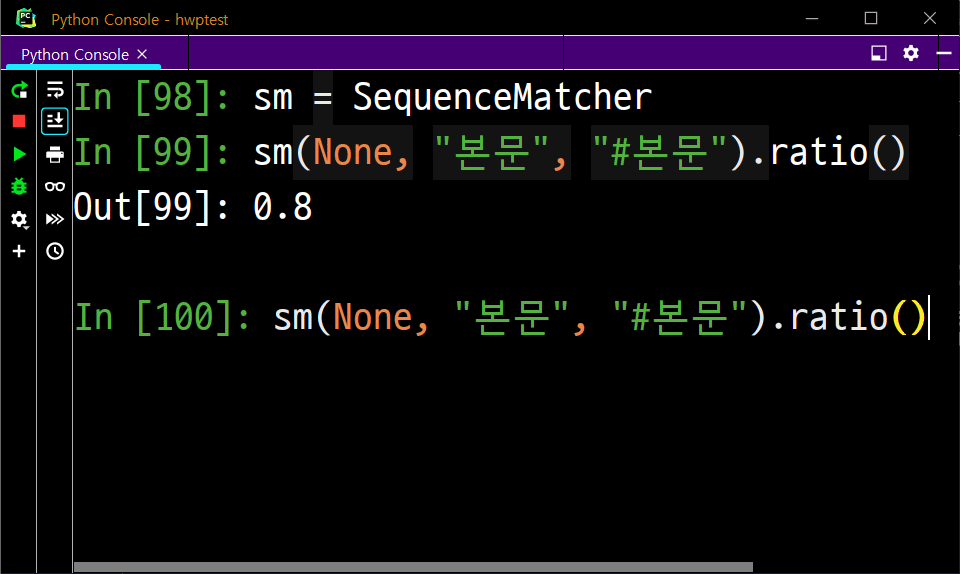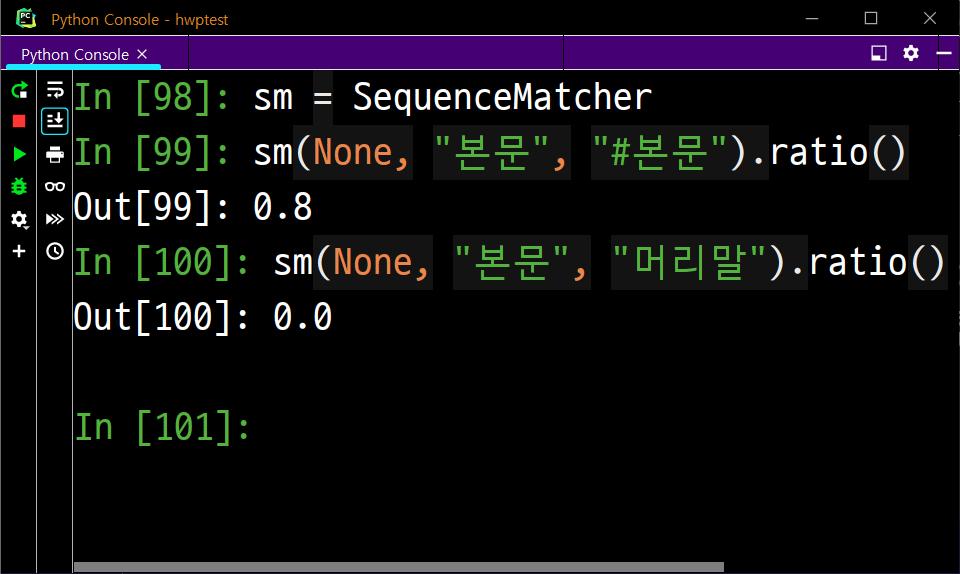
우리는 나머지 모든 문자열과 비교를 통해서 가장 유사도가 높은 문자열과 매칭을 해 주는 코드만 짜면 됩니다.
잘라서 설명하자니 복장터질 것 같네요.
아래는 이후 코드입니다.
from difflib import SequenceMatcher
템플릿 = ["바탕글", "본문", "개요 1", "개요 2", "개요 3", "개요 4", "개요 5",
"개요 6", "개요 7", "개요 8", "개요 9", "개요 10", "쪽 번호", "머리말",
"각주", "미주", "메모", "차례 제목", "차례 1", "차례 2", "차례 3", "캡션"]
취합문서 = ["## 바탕글", "#본문", "쪽번호", "머리말", "각 주", "미 주", "(메모)",
"개요.1", "개요 2!", "개요3", "개요-4", "개요@5", "개요 6?", "개요,7", "개요=8",
"개요~9", "개요_10", "캡 션", "차례제목", "차례-1", "차례-2", "차례-3"]
최대유사도리스트_매치결과 = []
for i in 템플릿:
유사도리스트 = [SequenceMatcher(None, i, j).ratio() for j in 취합문서]
최근접_인덱스 = 유사도리스트.index(max(유사도리스트))
최대유사도리스트_매치결과.append([i, 취합문서[최근접_인덱스]])
print(최대유사도리스트_매치결과)
최대유사도인덱스 = [[i, 취합문서.index(j)] for i, j in 최대유사도리스트_매치결과]
print(최대유사도인덱스)
위 코드를 한 줄씩 실행해보면서 결과를 확인하겠습니다.

원하는대로 잘(잘 정도가 아니고 완벽하게) 매치가 되었습니다.
리스트컴프리헨션을 조금 응용해서 코드분량을 줄여보았는데,
당장 이해가 되지 않더라도 영어문장 읽듯이 차근차근 읽어보시면 금방 이해하실 수 있을 것입니다.
마치며
아마 다음 포스팅이 이번 HDMI 시리즈의 마지막이 될 것 같습니다.
매치결과를 토대로 취합문서의 스타일을 템플릿에 맞게 변경하는 작업만 더 해보고 마치겠습니다.
실습해보시면서,
막히는 부분이나 질문은 댓글로 남겨주세요!
'아래아한글 자동화 > python+hwp 중급' 카테고리의 다른 글
| [HDMI] 최종화 : 취합문서 스타일 교정 (1) | 2022.12.08 |
|---|---|
| [HDMI] 진짜 본격적으로 header.xml 파헤쳐보기 (0) | 2022.12.07 |
| [HDMI] 본격적으로 xml 파헤쳐보기 (0) | 2022.12.07 |



댓글