
pyhwpx.Hwp().find_replace_all(src, dst, regex=True)
regex=True로 설정하면
re.sub와 동일한 방식으로 정규식 문법을 사용할 수 있다.
예를 들어 주민등록번호 패턴인
123456-1234567을 123456-1******로 변경하고자 하면,
(여러가지 구현이 있겠지만)
src = r"(\d{6})-(\d)\d{6}(?=\D|$)"
dst = r"\g<1>-\g<2>******"
hwp.find_replace_all(src, dst, regex=True)라고 코드를 입력하고 실행해보자.
시연화면은 아래와 같다.
바뀌기 전의 원본문서는 아래와 같고
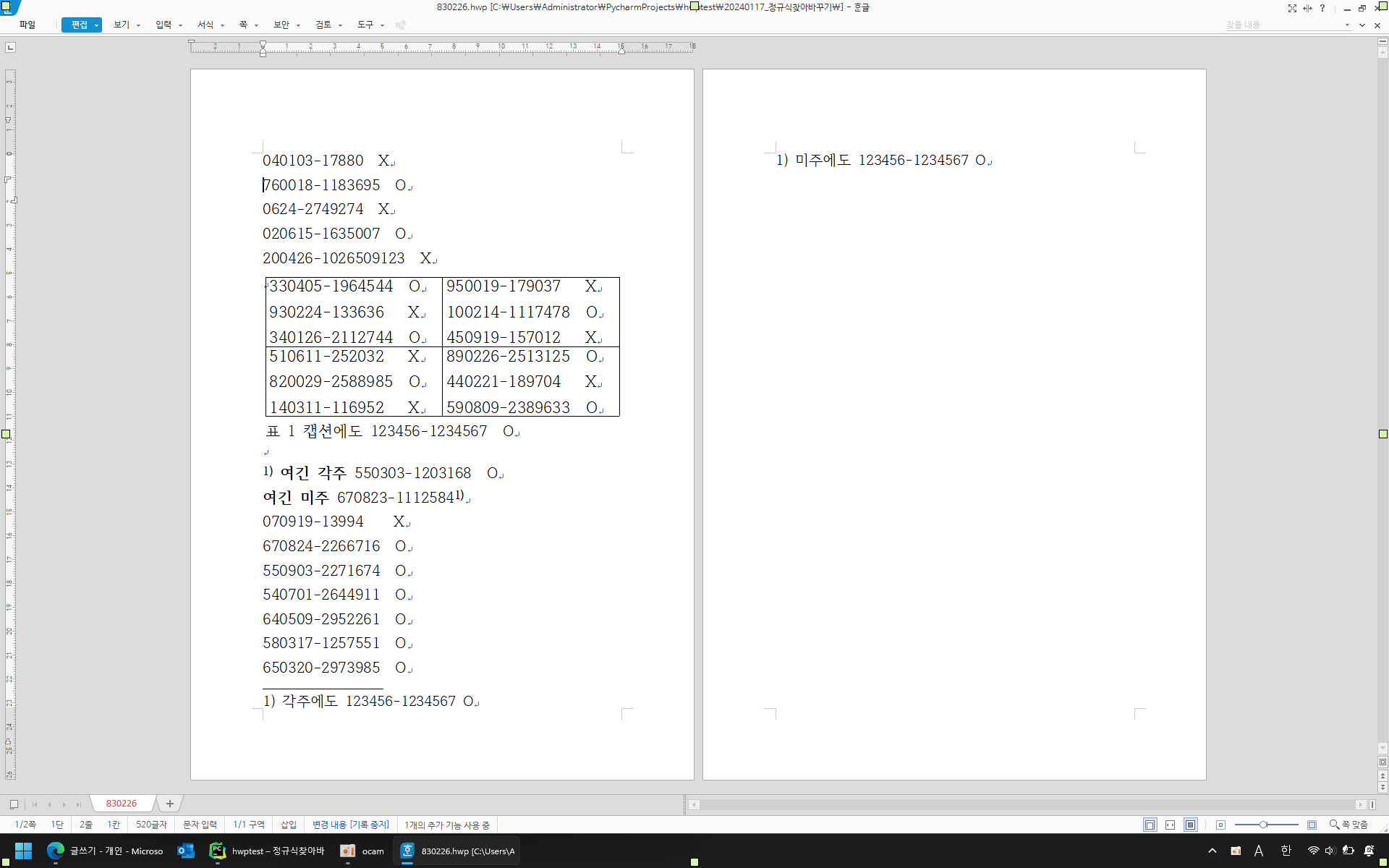
정규식 찾아바꾸기를 적용한 후의 문서는 아래와 같다.
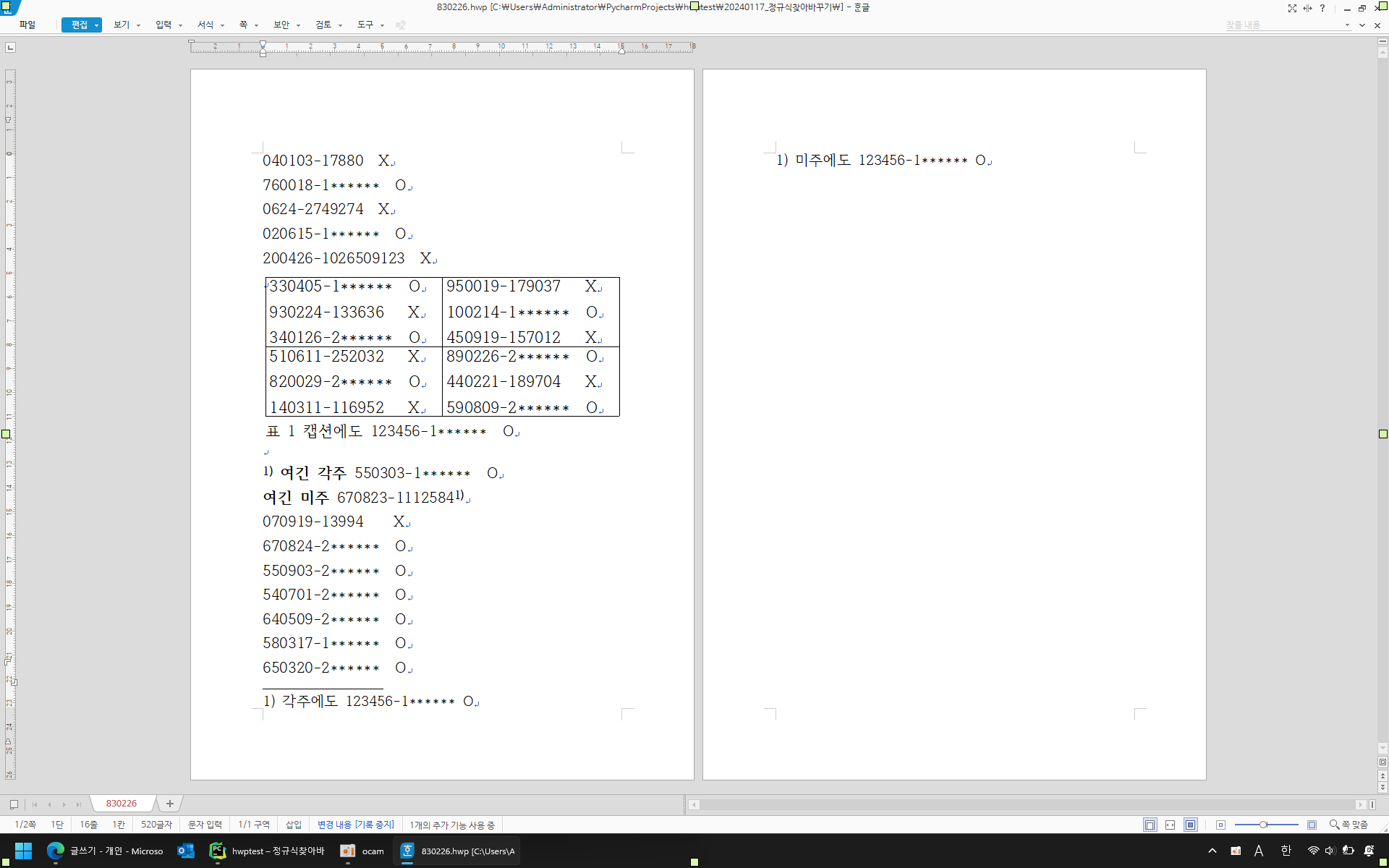
메서드 내부에서는 re.sub를 사용하지 않는다.
그 이유는 아래 접은글에
기존에 개인적으로 정규식 찾아바꾸기를 활용하던 방식은,
InitScan 및 GetText를 통해 한 문단씩 텍스트를 가져와서
re로 수정한 후 다시 한/글에 붙여넣는 방식이었는데
이 방법은 서식이 완전히 사라지거나, 미주/각주 등을 인식하지 못한다든지
하여튼 제한적이었다.
현재 메서드 안에서 사용하는 방식은,
GetTextFile로 문서 내 문자열 정보만 가져와서,
src_list만 찾은 후,
정규식 패턴과 re.sub를 통해 dst_list를 만든다.
그리고 해당 src와 dst로 일반 찾아바꾸기 메서드를 수행한다.
다소 무식한 방식이 아닐 수 없는데,
더 좋은 해법을 찾지 못했다.
아쉽게도 현재 버그가 하나 있다.
**미주**의 경우에는 미주번호가 본문의 끝에 바로 이어서 오는 것으로 인식되기 때문에
위의 예제에서도 미주가 달린 본문의 주민등록번호는 변경하지 못했다.
본문 중간의 미주가 들어있는 라인 끝의 1112584¹ 을 11125841인 8자리 정수로 이해하기 때문에
정규식 매치에서 제외되어버렸다. 좋은 방법이 없을까?ㅜ
포스팅을 남기다 번뜩 든 생각인데,
InitScan / GetText만 사용해서 컨트롤 없이 본문만 한 번 찾아바꾸기를 돌리고,
나머지 기타영역은 GetTextFile을 이용해서 위 방식으로 돌리는,
두 단계 방식이면 위 문제가 해결될 것 같다. 조만간 다듬어서 업데이트해야지!ㅋ
'아래아한글 자동화 > pyhwpx 사용법' 카테고리의 다른 글
| [pyhwpx] 한/글 자동화 문의 및 요청의 90%는 ㅇㅇ 관련이었어요. (0) | 2024.01.25 |
|---|---|
| [크롤링 연계2] 보건소 정보로 한/글 파일 만들기 (2) | 2024.01.23 |
| [크롤링 연계1/2] 전국 보건소 정보 가져오기 feat.질병관리청 (0) | 2024.01.23 |



댓글