
반응형
한/글의 표를 csv나 판다스 데이터프레임(df)로 저장할 때
곤혹스러운 경험을 하신 적이 있을 거예요.
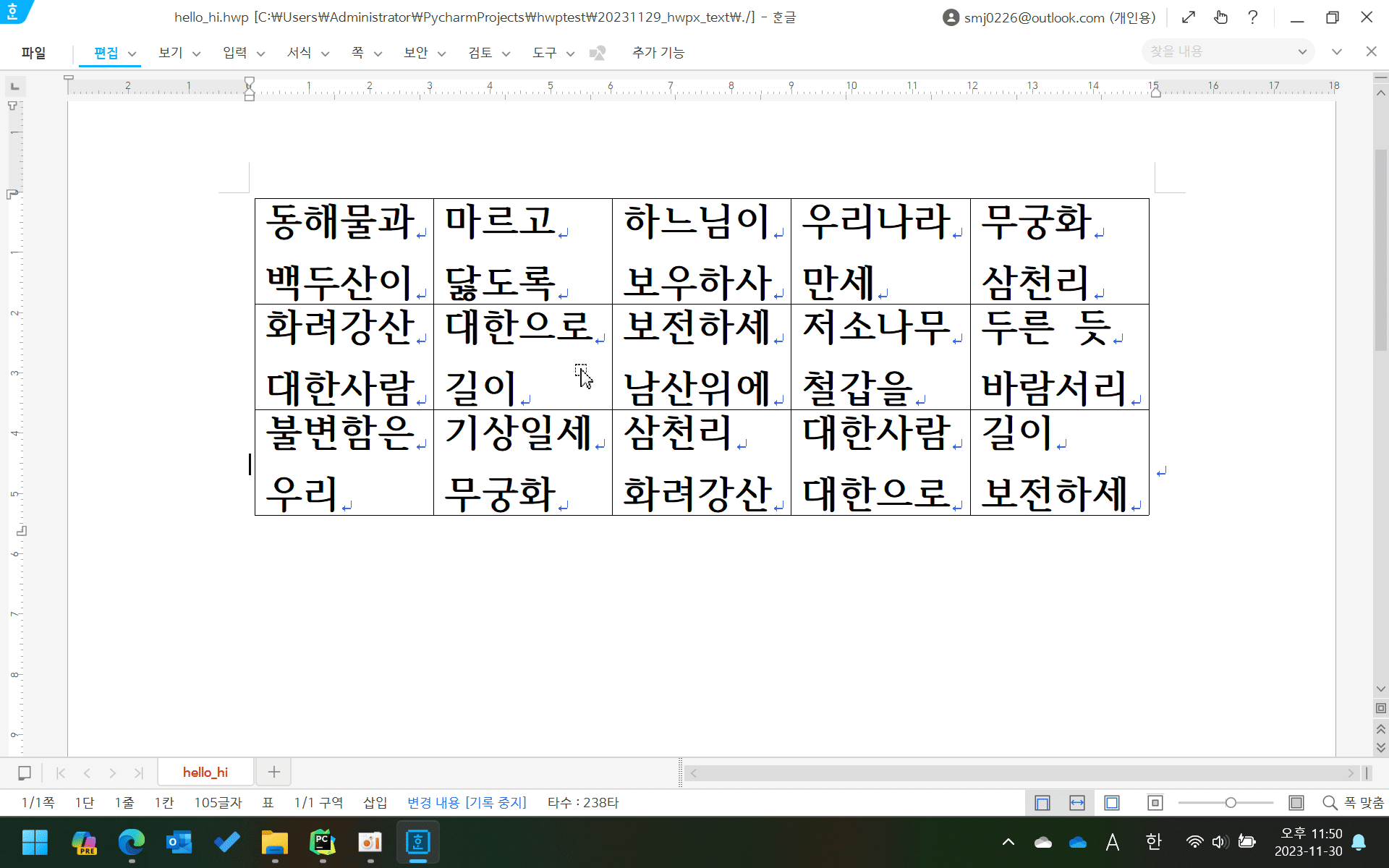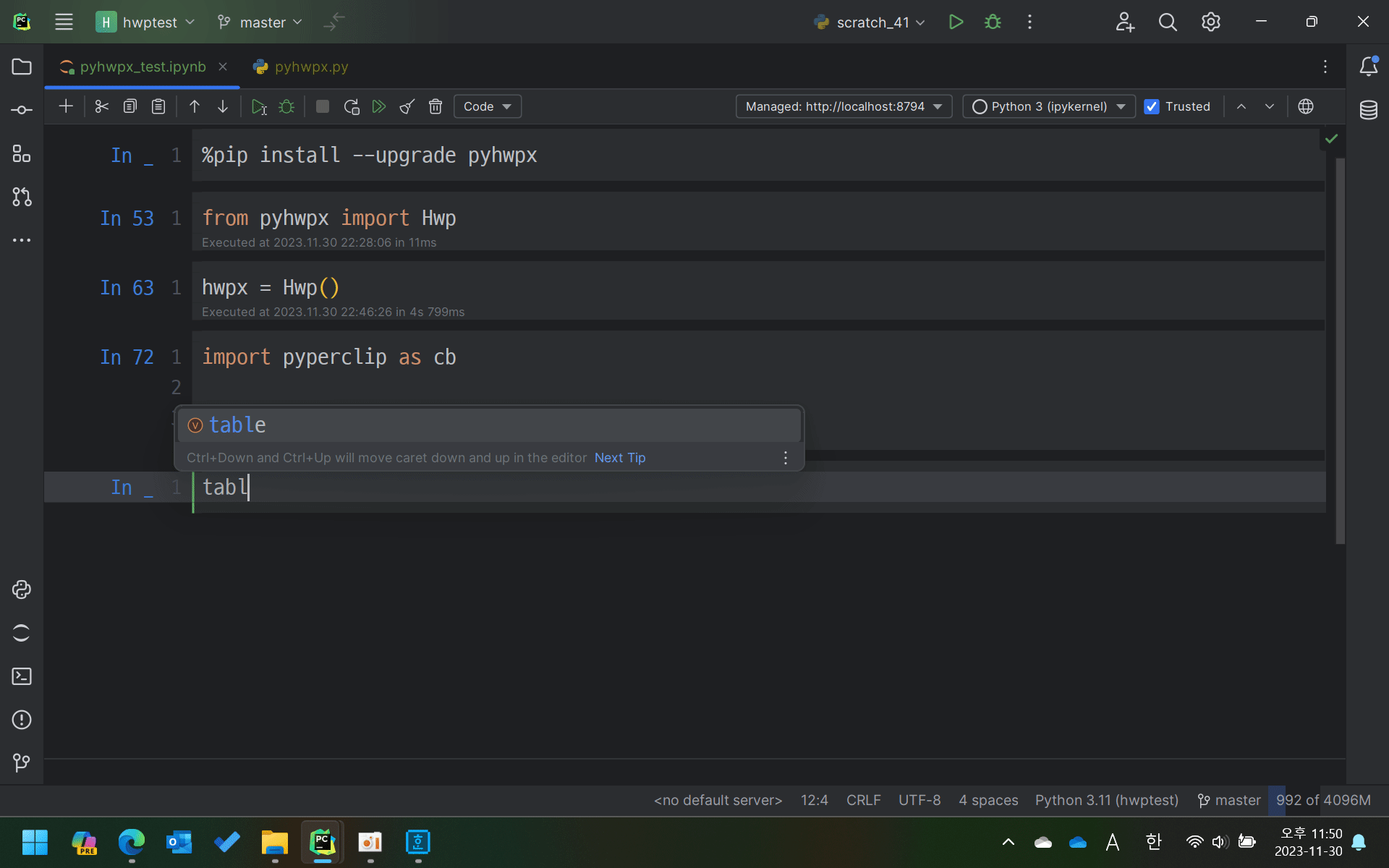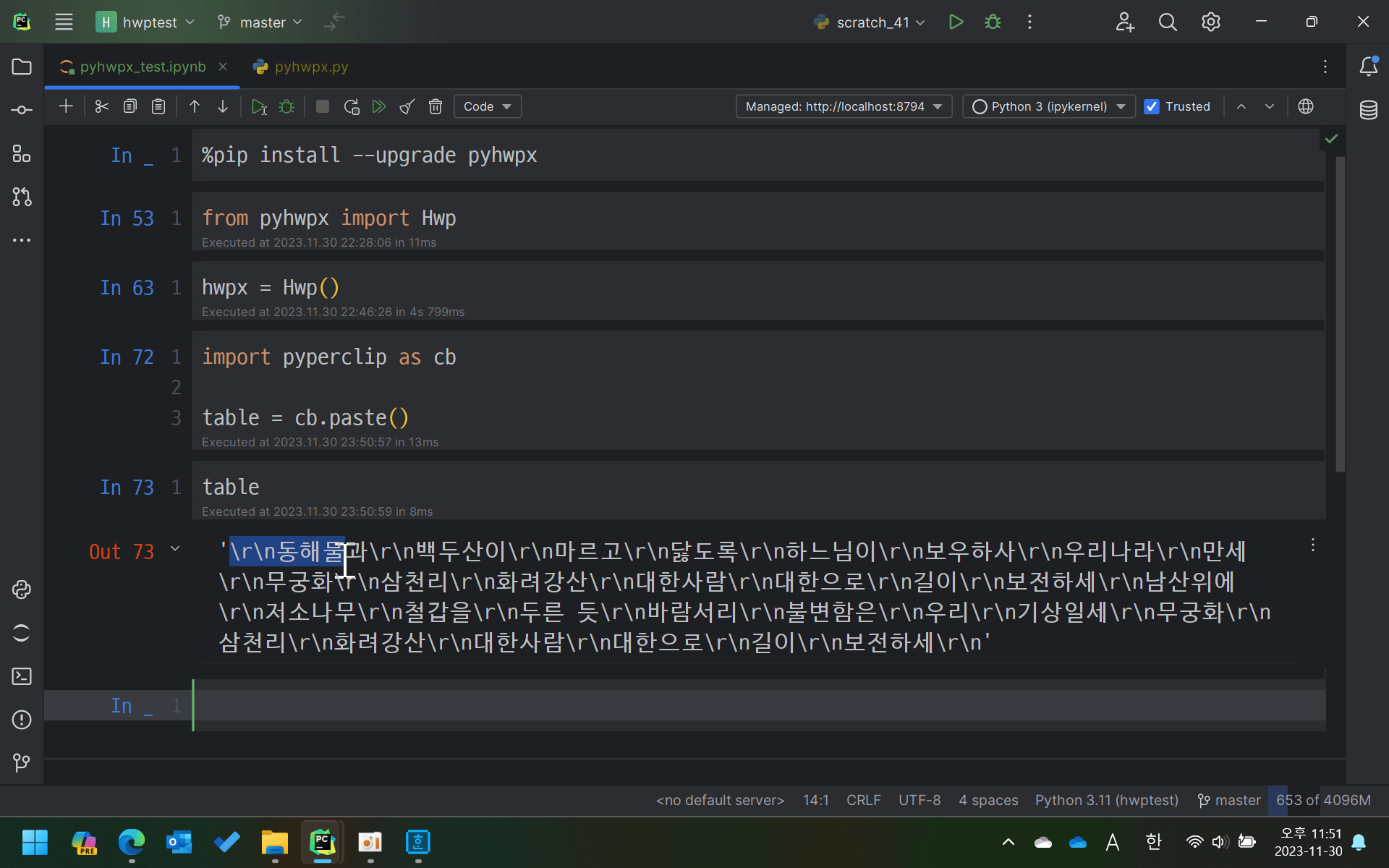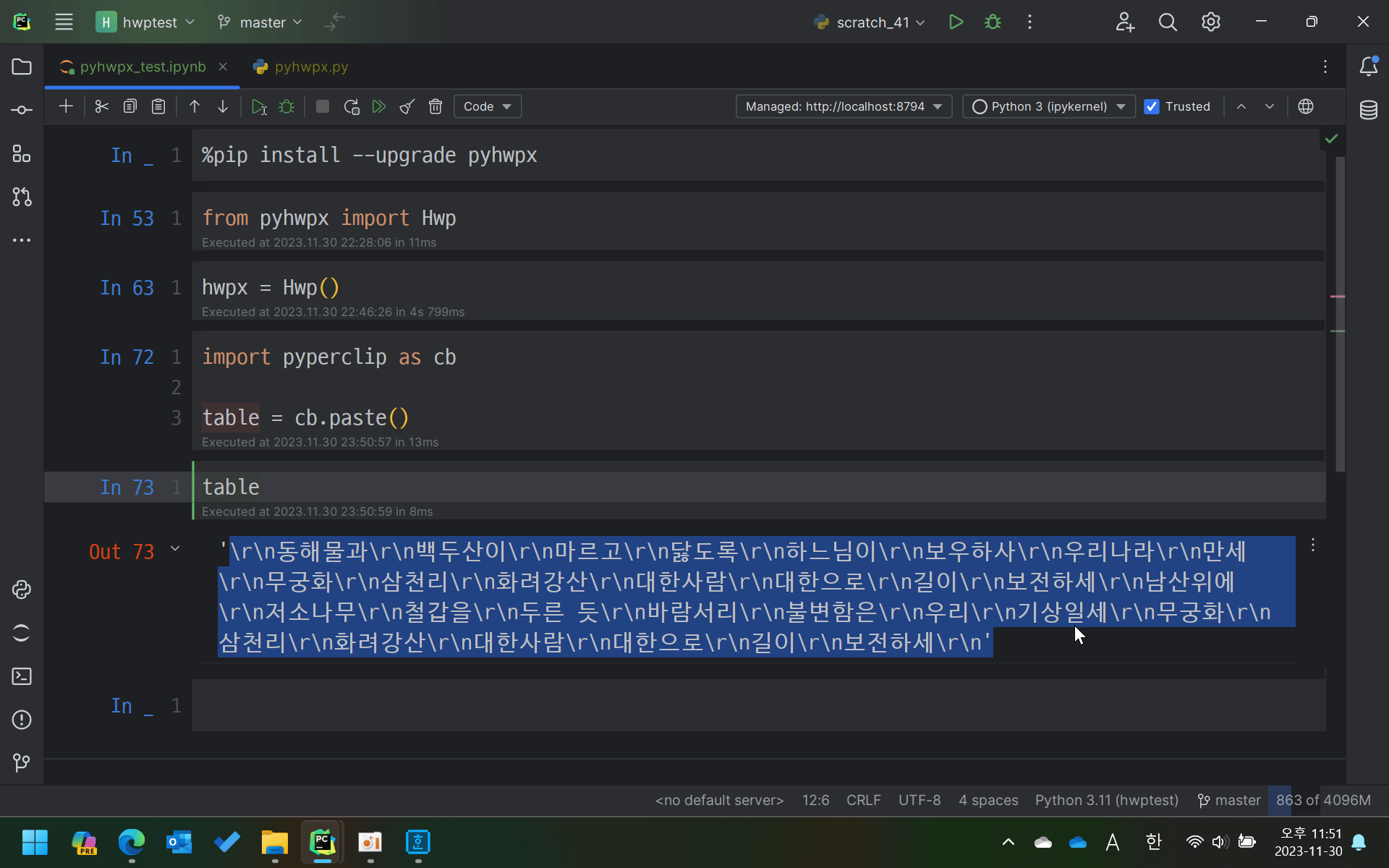
왜냐면 한/글의 표를 클립보드에 복사하고 붙여넣기해보면
행 구분 없이 전부 줄바꿈(\r\n) 기호로만 구분된 문자열이 되거든요.

'그럼 표의 모양(3행5열)을 기억해 뒀다가 적당히 잘라서 저장하면 되지 않나?'
이렇게 생각하실 수도 있지만,
아래와 같이 셀 안에 줄바꿈이 있는 경우는 더욱 난처해지죠.
그래서 pyhwpx에서는
table_to_csv, table_to_df 메서드를
제공하고 있습니다.
한 번 사용해볼까요?ㅎ
캐럿은 아무데나 두고
아래와 같이 실행하면
문서 첫 번째 표를 csv로 변환해요.
(n번째 표는 idx=n이라고 파라미터를 추가하시면 돼요.)
hwpx.table_to_df(
filename="a.csv",
encoding="cp949"
)
csv로 저장하는 과정 내부적으로는
판다스 데이터프레임을 활용하고 있어요.
df로 변환한 후에 df.to_csv 메서드를 쓰고 있습니다.
이와 비슷한 메서드로
판다스 데이터프레임으로 직접 변환해주는 table_to_df도 사용해볼게요.

사실 df는 어느 포맷으로든 저장하기 편하잖아요^^
df.to_excel(저장할_엑셀파일명, index=False)을 실행하면 엑셀파일이 생성되고요.

API에서 제공하는 기본 명령어 외에도
이런 식으로 유용할 것 같은 메서드를 추가해보고 있는데요.
혹시 업무에 필요하시거나, 유용하게 사용할 수 있을 것 같은 메서드를 제안해주시면
업데이트 때 우선하여 적용해보겠습니다.
많은 참여 부탁드립니다.
감사합니다.
행복한 하루 되세요^^
반응형
'아래아한글 자동화 > pyhwpx 사용법' 카테고리의 다른 글
| [예제] 특정 단어들에다 메모교정표 삽입하기 (0) | 2023.12.06 |
|---|---|
| 문서를 불러와서 저장하거나 다른이름으로 저장하는 방법 (2) | 2023.11.30 |
| 두 개 이상의 문서를 동시에 열어서 편집하고 싶은 경우 (0) | 2023.11.30 |




댓글